TL;DR — Within six months, AI models will cost nearly nothing to run. Demand won't drop — it'll explode. But the companies charging $3–15/M tokens are about to get destroyed by open-source, and they won't see it coming. Some stocks crater. Others — power, open-source infrastructure — quietly win. Here's the thesis and where I'm placing bets.
How many of you actually tried Opus 4.8?
Not many. And that's the tell. A year ago, every frontier model drop caused a collective freakout — benchmarks everywhere, Twitter threads, everyone running their test prompts. Now Anthropic ships a new flagship and the response is a collective shrug. Developers are busy. They already have something that works. And honestly? They're not sure the upgrade is worth re-evaluating their stack.
The big lifts already happened. We crossed "good enough" faster than anyone expected. In code, we've already hit zero: switched our stack to open-source, saved hundreds of thousands of dollars, benchmarks didn't move. What's left is pricing and switching cost. Commodity battles. And in commodity battles, the cheapest credible option wins.
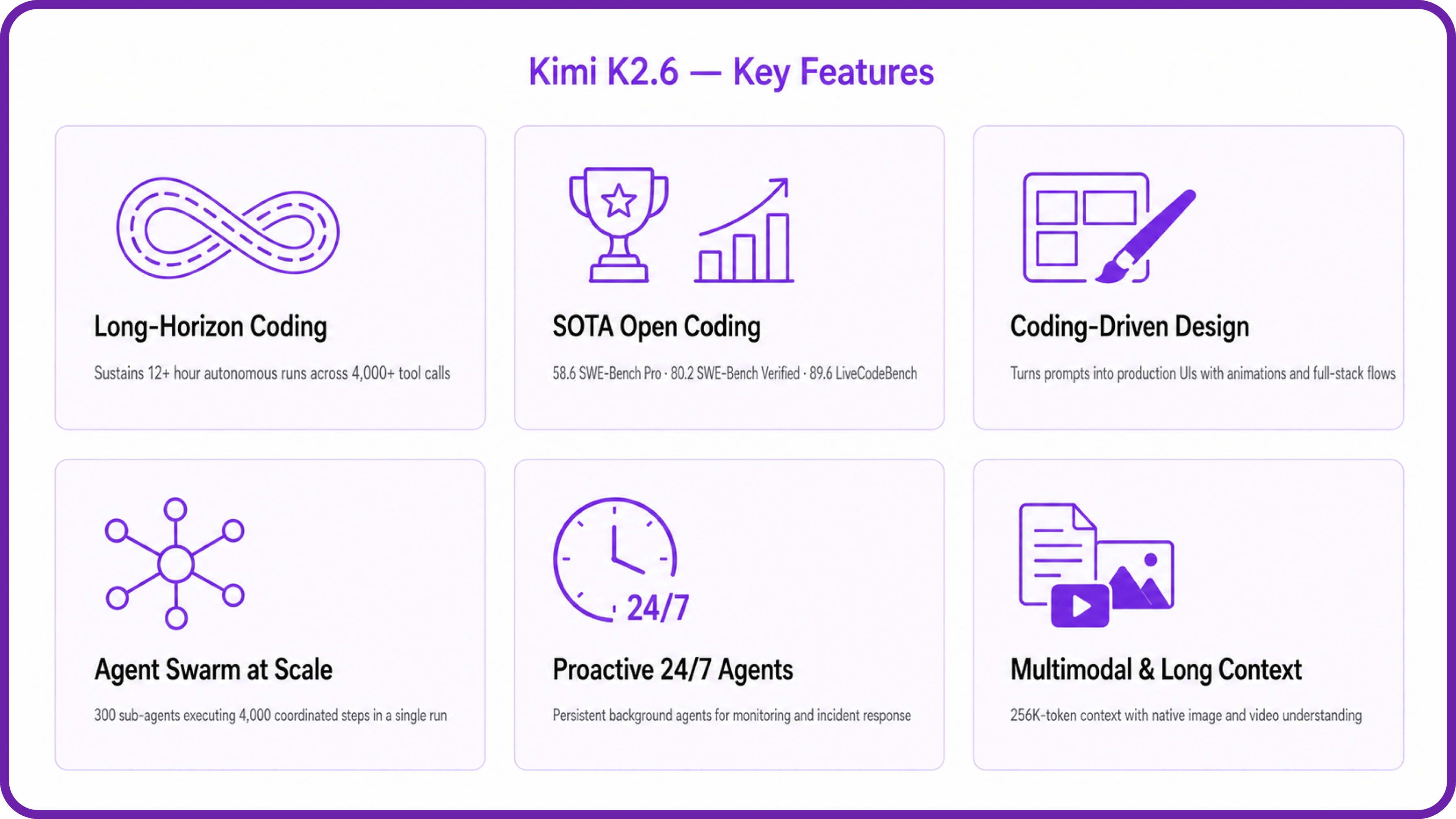
In April 2026, Moonshot AI shipped Kimi K2.6 — an open-weight model from a Beijing lab. It scores the exact same as GPT-5.5 on SWE-Bench Pro. On the broadest agentic reasoning benchmark, it trails Claude Opus 4.7 by less than one point. This is not a Chinese model that's "almost good." It's a Chinese model that ties the US frontier on coding.
The price: $0.95 per million input tokens.
But headline prices are the wrong number for agents. Agents mostly pay for cache reads — every loop re-attaches the same system prompt, codebase, conversation history. That prefix is cached. That's the cost that compounds.
| DeepSeek V4 Flash | MiniMax M2.5 | Kimi K2.6 | Claude Sonnet 4.6 | |
|---|---|---|---|---|
| Cache read | $0.02 / M | $0.03 / M | $0.16 / M | $0.30 / M |
| Output | $0.20 / M | $1.20 / M | $4.00 / M | $15.00 / M |
| Fresh input | $0.10 / M | $0.30 / M | $0.95 / M | $3.00 / M |
One realistic agent step — 80K cached context, 10K fresh input, 10K output:
| DeepSeek V4 Flash | MiniMax M2.5 | Kimi K2.6 | Claude Sonnet 4.6 | |
|---|---|---|---|---|
| Per call | ~$0.005 | ~$0.017 | ~$0.062 | ~$0.20 |
| 10K calls / day | ~$50 | ~$170 | ~$620 | ~$2,040 |
That's not a pricing difference. That's a different category of what's possible to build.
Anthropic and OpenAI Are Charging You Prices That No Longer Make Sense
Anthropic and OpenAI are wildly overpriced given what Chinese labs have already demonstrated.
A Beijing lab ships a model that matches the US frontier at 15–25x lower inference cost. That's not a fair market price for intelligence — that's a monopoly premium that collapses the moment a credible alternative exists.
That alternative now exists. Multiple ones. You don't need Anthropic to generate value. OpenRouter runs 400+ models, 8 million developers, 25 trillion tokens a week. The routing layer is already built.
The window to respond is probably six months to a year. When something developers trust in production at scale drops on open-source, enterprise contracts won't renew at current prices.
Here's the sharpest irony: Dario Amodei wrote this himself:
"If these scaling laws continue for only a year or two longer, we are likely to get what I've called Powerful AI, or 'a country of geniuses in a datacenter'."
A country of geniuses in a datacenter. His words. His company is building toward a world of near-infinite intelligence abundance — and simultaneously charging $15 per million output tokens to access it. Those two things cannot coexist for long. Either the abundance arrives and the price collapses, or the price holds and the abundance never materializes. Dario is betting on the former. His pricing team hasn't caught up yet.
I'm not saying Anthropic and OpenAI disappear. I'm saying their current pricing model — and the valuation multiples that depend on it — does not survive contact with what's already been built.
How China Got Here: Distillation as Industrial Strategy
How did labs constrained by export controls close the gap this fast?
Anthropic's May 2026 paper — "2028: Two scenarios for global AI leadership" — names it directly. They call it distillation attacks: thousands of fraudulent accounts on US AI platforms, systematically harvesting model outputs to replicate frontier capabilities at scale.
"The result is near-frontier capability at a fraction of the cost, subsidized by the United States. It is systematic industrial espionage of a technology critical to long-term US national security interests."
A state media outlet in China described distillation as the "back door" their labs depend on. An ex-ByteDance researcher confirmed PRC labs use it to avoid building their own data pipelines.
The economic implication is stark: you can reach near-frontier capability without the full cost of original research — and when you build on distilled knowledge with radically lower inference costs, you compete on price in ways the original innovators structurally cannot match. Anthropic spent billions training Claude. Beijing labs harvested the output, compressed the knowledge, and rebuilt it in 32B active parameters at a fraction of the serving cost.
This is not just espionage. It's an efficiency weapon.
The Architecture That Changed Everything: MoE and KV Cache
In 2017, the landmark paper was titled "Attention Is All You Need." Nobody runs that architecture anymore. That's the quiet revolution underneath everything.
MoE first. Kimi K2.6 has 1 trillion parameters — but activates only 32 billion per token. The model trains on massive data across all its capacity, then at inference routes each token through only the experts it needs. You get frontier-level knowledge baked in at a fraction of the compute cost to serve it. A trillion-parameter model, served as cheaply as a 32B one. This is the core trick that makes Chinese pricing economically sustainable while US labs are still serving dense models.
KV cache second. Classical transformers attend to every previous token. At 1M context, that's quadratically insane — the memory alone would exceed any GPU in existence. DeepSeek's solution is to stop pretending attention means "look at everything."
DeepSeek's insight: stop treating KV cache as a dumb buffer. Treat it as a memory system.
They built a three-tier architecture — CSA + HCA:
- Recent context: uncompressed, exact
- CSA (mid-range): compresses 4 tokens → 1 KV entry, with a "lightning indexer" that retrieves only relevant chunks per query — retrieval, not scanning
- HCA (far context): compresses 128 tokens → 1 entry, dense attention over the tiny result
It's L1 cache → L2 cache → disk. But inside the transformer.


The result: DeepSeek V4 Pro needs only 10% of the KV cache memory of its predecessor for 1M-token contexts. That makes serving a million-token model economical. For agents specifically: the dominant cost isn't generation, it's re-reading the same cached prefix on every call. With shared-prefix reuse, an agent scanning the same codebase 500 times pays for that context once.
These techniques — MoE, hierarchical KV compression, shared-prefix caching — are now in the public literature. Every open-source lab is implementing them. Every cloud provider is building on them. The cost curve is not stopping.
The Sufficiency Threshold — And Why It Has a Floor
Call it decision-grade intelligence: capable enough for code review, threat analysis, contract drafting, research summarization — at a price so low it disappears from your budget. That's where the MoE tier is already landing.
But there's a hard floor. The compression trick works because most queries only need a subset of expertise — route coding questions through code experts, legal questions through legal experts. You get 90% of the capability at 3% of the inference cost. The remaining 10% — deep cross-domain scientific reasoning, novel security research, drug modeling — needs something bigger than 32B active parameters.
The Two-Tier World: Commodity vs. Restricted Expert Access
Fable changed how I think about this.
When Anthropic restricted access to Fable, most people read it as a safety story. I think it's a business model story.
Tier 1 — Commodity (open, near-free): DeepSeek, Kimi, MiniMax. Handles the 90%. Anthropic and OpenAI lose this tier — they cannot compete on price.
Tier 2 — Restricted Expert (gated, contractual): Domain-specialized frontier models with institutional access controls. The Cyber Expert licensed to Palo Alto Networks and the DoD. The Bio Expert to Pfizer and DARPA. Not "sign up for an API key" — "you need a contract, a compliance review, and probably a security clearance."
The jailbreak problem makes tiering inevitable. An unconstrained bio-expert is a bioweapon design tool. An unconstrained cyber expert generates novel zero-days at scale. The question isn't whether access controls get imposed — it's how fast.
This is the survival play for Anthropic and OpenAI: not competing on price, but owning the restricted expert tier that open-source legally cannot serve. Think Bloomberg Terminal for intelligence — expensive, sticky, institutional.
The Pattern: What Gets Built, Then Killed
I've watched this cycle repeat in four years of building AI tools for security.
Act 1: A model limitation creates a constraint — context too short, too expensive, too unreliable.
Act 2: The ecosystem builds an elaborate workaround. RAG pipelines. Vector databases. Context management layers. Entire companies funded on the complexity.
Act 3: The models improve. The limitation disappears. The workaround becomes overhead.
RAG is already collapsing. Models now have 200K–1M token windows. The retrieval step adds latency and errors without adding intelligence. You can just put the documents in context.
Context engineering is next. The elaborate logic for selecting what to include, what to summarize — it exists because context is expensive. When context costs a fraction of a cent per million tokens, that logic becomes a liability.
Every clever workaround for a model limitation is also a maintenance burden, a failure mode, and technical debt waiting to expire.
One Small Model, Tools, and Code Execution
Where this heads isn't complicated to describe: one small, cheap, capable model + tools + code execution replaces most of what currently requires expensive models and complex pipelines.
The prompt engineering layer, the retrieval layer, the orchestration layer — it all migrates into the model. What's left is the product insight: what problem are you actually solving, and can you build something people will pay for?
This is where SaaS comes back.
The model commoditizes the orchestration layers. In security, the ability to run a capable model over every binary, every package, every log — continuously, cheaply — isn't fully here yet. But it's close. When it arrives, the bottleneck shifts from "can we afford this" to "do we know what to do with the answers." That's a much better problem to have.
The Model Underneath Doesn't Matter Anymore
Greg Isenberg put it well last week:
"We're entering the era where model releases feel like iPhone releases. 4.6 to 4.7 to 4.8 — slightly better camera, nobody can agree if it's better or worse. I think we're maybe 6 months from nobody caring which model they're using the way nobody cares which engine is in their Uber."
What moved the needle that same week: Claude Code shipping dynamic workflows. Codex shipping a desktop app. The tooling. Not the model.
Cursor is the clearest proof. In March 2026, they launched Composer 2 as "frontier-level coding intelligence." Within hours, developers found Kimi K2.5 identifiers in the API logs — the open-weight Beijing model powering Cursor's flagship agent.
Cursor hadn't just wrapped it. They ran Kimi K2.5 through continued pretraining on code, then large-scale RL in simulated real Cursor sessions. Code is the first domain where this works cleanly at scale — tests pass or they don't, so the reward signal is automatic and you can generate trillions of training examples without human labelers. The result: 37% better on their internal benchmark, priced at $0.50/M input. The moat isn't the foundation model. It's the RL training, the task distribution, the domain knowledge baked in.
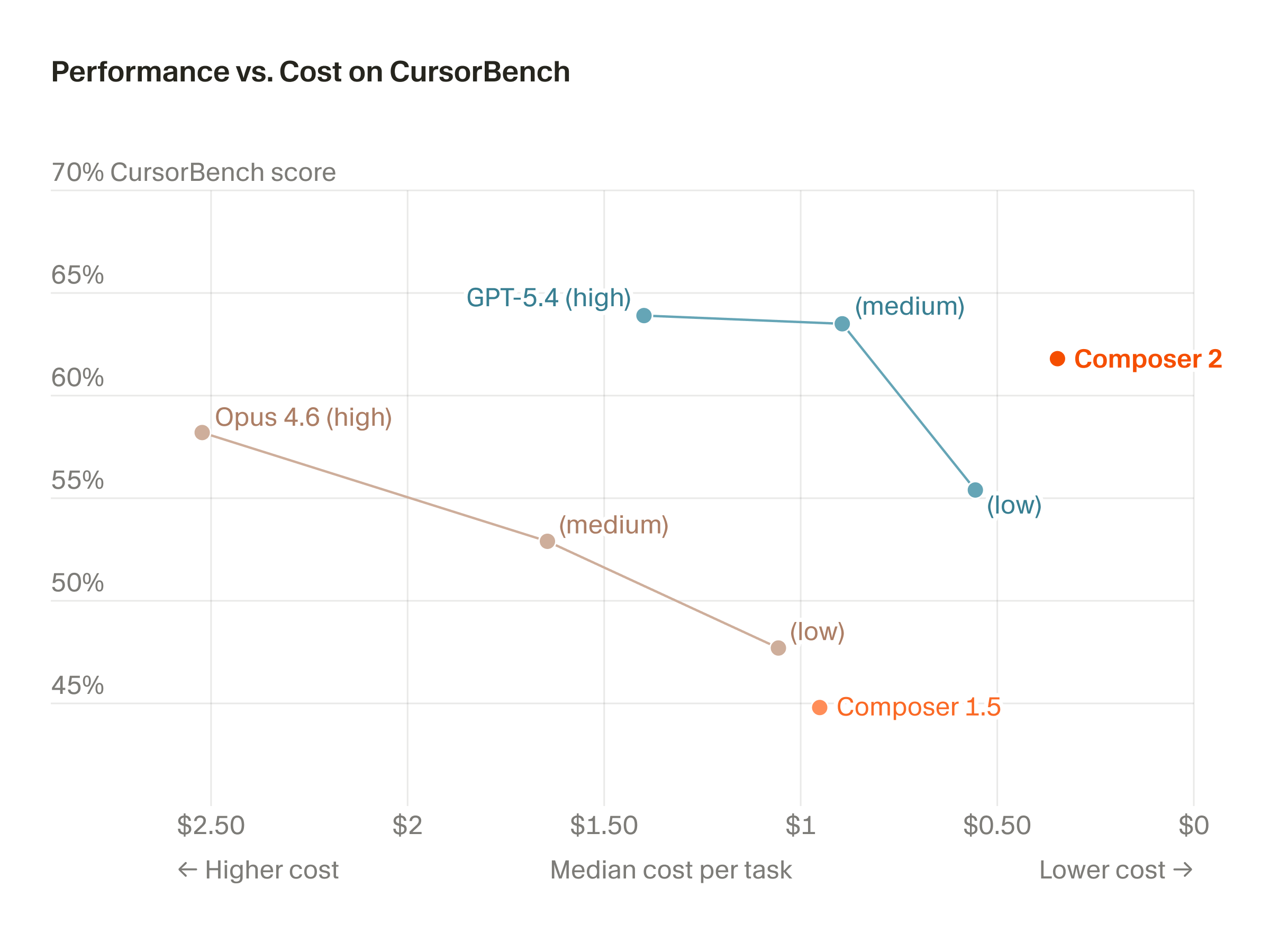
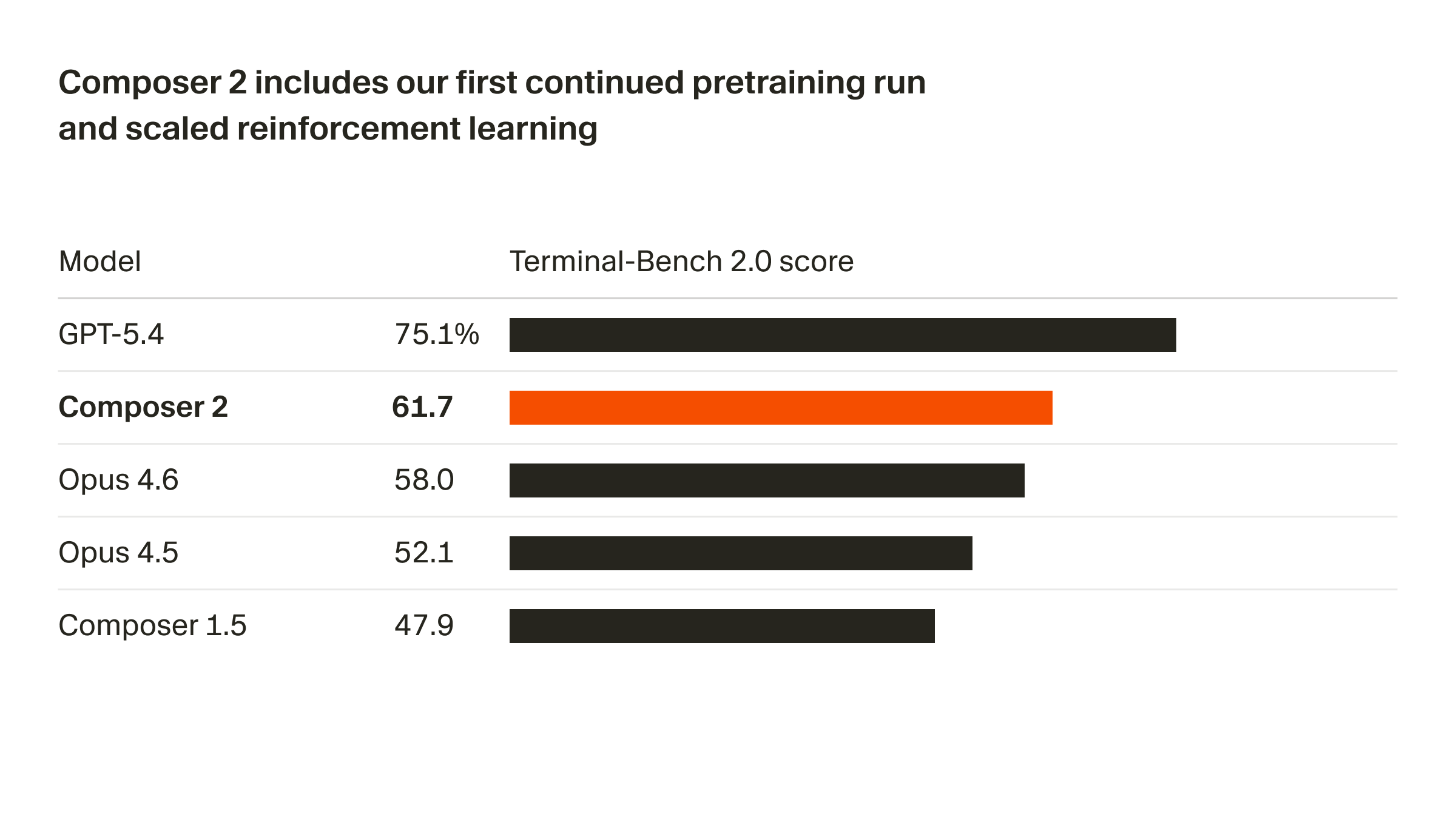
Cursor is a $30 billion company built, in meaningful part, on a Beijing model at $0.60/M tokens.
OpenRouter raised $113M — CapitalG, NVIDIA, Snowflake, Databricks. 5x token volume growth in six months. 8 million developers. 400+ models. The routing layer exists because the model underneath has become interchangeable.
What Comes Next: Harnesses and Evals
Most teams are locked into expensive frontier models not because cheap ones aren't capable enough — but because they have no way to know. No evals, no regression tests, no confidence. That uncertainty is what keeps enterprises paying $0.30/M cache reads when $0.02/M exists.
The value isn't the AI — it's the ability to stay on the right side of the cost curve as it falls. Teams with proper eval infrastructure switch in days when a new cheap model drops. Everyone else spends months rebuilding the confidence the eval suite already provides.
The second category of winner: startups that build assuming intelligence is already free. What would you build if running a capable model over every event, every file, every log line cost essentially nothing? A security audit on every commit. A code reviewer that reads the full codebase before every PR. These weren't hard to build — they were unaffordable.
At $0.002 per call, they're not.
Nothing in this post is financial advice. These are my personal views on a market thesis I find compelling. Do your own research before trading anything.